
Recently I upgraded a VMware Cloud Foundation 4.2.1 environment to the latest version 4.3.1. Although the upgrade is pretty straightforward I ran into some issues with vRealize Automation that were solved with the help of VMware’s GSS team.
To upgrade from version 4.2.1 to 4.3.1 is an online Skip-Level upgrade supported. This only counts for the following components but not for the vRealize suite parts:
- vCenter Server
- ESXi
- NSX-T Data Center
VersionAlias.yml
During the upgrade steps the SDDC Manager will go step-by-step to the right upgrades with the possibility to download the bundle or start the update. Although this was the case with most of the VCF components the upgrade to version 8.4.1 of vRealize Automation (part of VCF 4.3) didn’t pop up.
A review of the bundle for VRA 8.4.1 in SDDC manager shows an requirement for version: 8.2.0-17018654

Unfortunately the version within VCF 4.2.1 was version 8.2.0-16980951. This is why the upgrade didn’t pop up. Within SDDC manager it’s possible to tell Lifecycle manager that some versions are equal to the required version. This can be done in file: /opt/vmware/vcf/lcm/lcm-app/conf/VersionAlias.yml. This file showed the following versions:
root@s0vsdm [ ~ ]# vi /opt/vmware/vcf/lcm/lcm-app/conf/VersionAlias.yml
versionAliases:
VRA:
- alias:
- 8.4.1-18054500
base: 8.2.0-17018654
To fix the upgrade process we changed the file input to:
root@s0vsdm [ ~ ]# vi /opt/vmware/vcf/lcm/lcm-app/conf/VersionAlias.yml
versionAliases:
VRA:
- alias:
- 8.2.0-16980951
base: 8.2.0-17018654You have to pay extra attention to the layout of the file as it only works with spaces and no other characters like Tab. As seen the base is the version needed by the Upgrade bundle and the Alias is the current version. Restart the LCM service to load the new file:
systemctl restart lcmIt can take up to 5 minutes for the SDDC Manager to initialize the LCM depot and make the upgrade available.
Failing upgrade
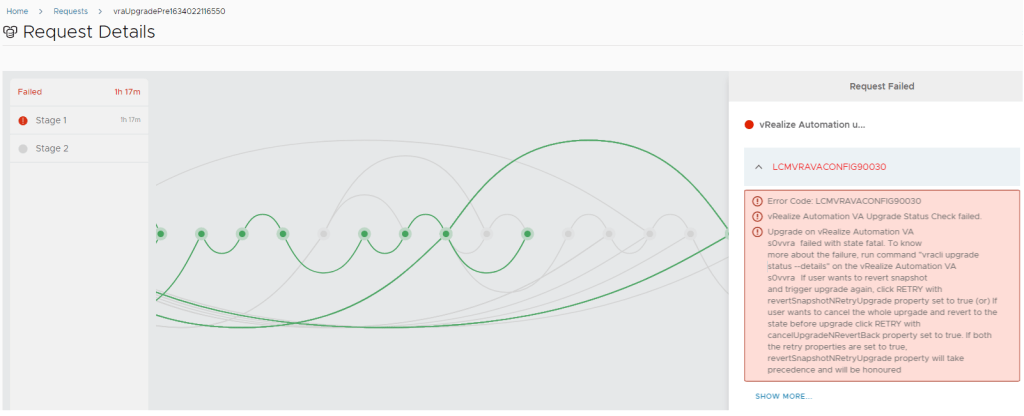
During the upgrade to version 8.4.1 the upgrade failed after about 1,5 hours. The error message in SDDC Manager doesn’t show much information about what happened.

As SDDC Manager asks the vRealize LifeCycle Manager instance to do the upgrade through REST API calls, more about the upgrade is found there.
root@s0vvra1 [ ~ ]# vracli upgrade status --details
Upgrade is in progress
...............................................................
Loading system configurations.
System configurations loaded successfully.
...............................................................
Deploying services. This might take a few minutes.
Services deployed successfully.
...............................................................
Running health check after upgrade for nodes and pods.
Health check after upgrade for nodes and pods failed.
... Upgrade terminated due to critical error. Follow the upgrade guide to recover the system. ...Well this wasn’t as helpful as I hoped for. I checked the current version and the running Kubernetes pods. Both looked fine at first. The cluster was running the new version and all pods were running
root@s0vvra1 [ ~ ]# vracli version
Version - 8.4.1.16947 Build 18054500
Description - VMware vRealize Automation Appliance 8.4.1
root@s0vvra1 [ ~ ]# kubectl -n prelude get pods -o wide
NAME READY STATUS RESTARTS AGE
vco-app-656cf667c8-9r869 3/3 Running 5 91m
vco-app-656cf667c8-bxhqg 3/3 Running 1 91m
vco-app-656cf667c8-tkp8z 3/3 Running 1 91m
Well there were ofcourse more pods running but these 3 were different than the others. At the RESTARTS column there are 5 restarts visible. It looks like this pod was holding back the upgrade till a time-out happened.
As everything looks good after the unready upgrade, we resumed the upgrade from the command-line. Important is to use the VRA node mentioned within vRLCM.
root@s0vvra1 [ ~ ]# vracli upgrade exec --resume
root@s0vvra1 [ ~ ]#vracli upgrade status --details
Upgrade Report
Summary
-------------------------------------------------------------------------------------
Date: Tue Oct 12 12:16:34 UTC 2021
Duration: 315 minutes
Result: Upgraded
Description: Upgrade has completed successfully and services have been restarted successfully.
Reference
-------------------------------------------------------------------------------------
Logs: /var/log/vmware/prelude
Backup: /data/restorepoint
Runtime: /var/vmware/prelude/upgrade
Some directories might not exist.
Version
-------------------------------------------------------------------------------------
Services
Before: 8.2.0.12946
After: 8.4.1.16947
Platform
Before: 8.2.0.12946
After: 8.4.1.16947
Cluster
-------------------------------------------------------------------------------------
Overall Status: Normal
Hostname: s0vvra1.fqdn
Status: Upgraded
Cluster Member: Yes
Version Before: 8.2.0.12946
Version After: 8.4.1.16947
Description: The node is upgraded successfully.
Hostname: s0vvra2.fqdn
Status: Upgraded
Cluster Member: Yes
Version Before: 8.2.0.12946
Version After: 8.4.1.16947
Description: The node is upgraded successfully.
Hostname: s0vvra3.fqdn
Status: Upgraded
Cluster Member: Yes
Version Before: 8.2.0.12946
Version After: 8.4.1.16947
Description: The node is upgraded successfully.
Ok, VRA has been upgraded successfully but how do we let SDDC Manager know? As vRLCM is managing the VRA environment we have to start there. Just trigger an Inventory Resync from the Enviroments page.
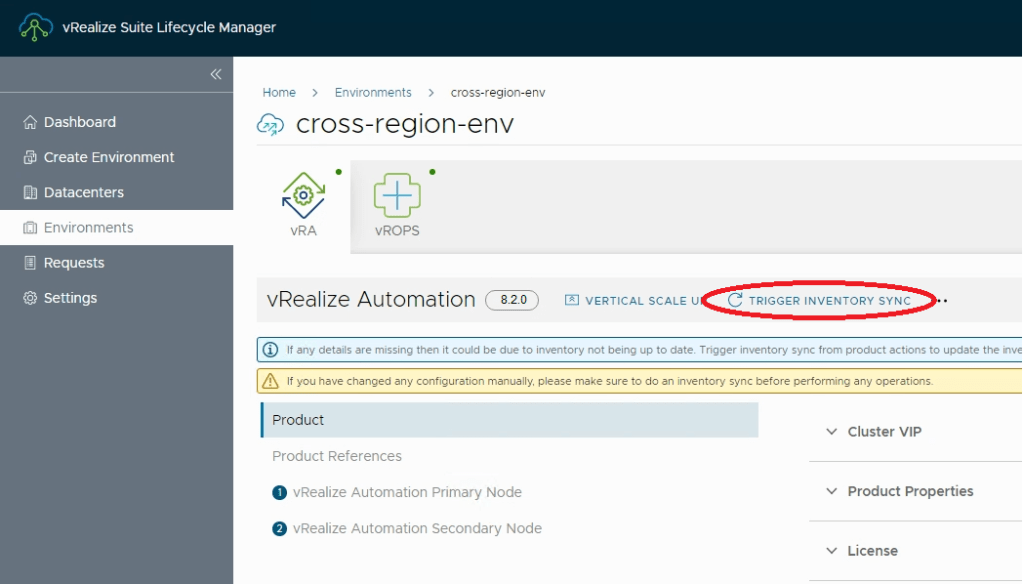
This also triggers an update to SDDC Manager to enable further upgrades.
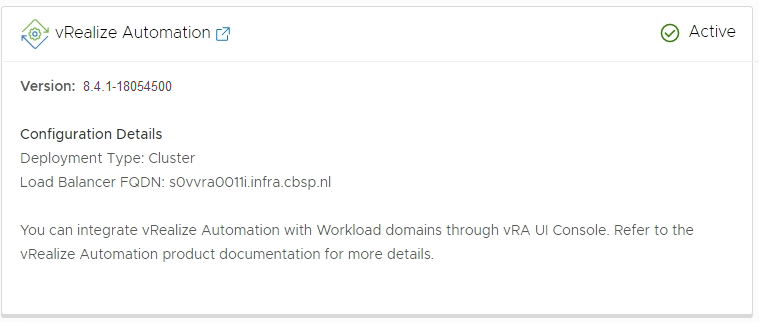
After this the upgrade to version 8.5 went smooth without any errors.

Leave a comment